
Sebuah langkah besar dalam komputasi kuantum telah dicapai oleh tim peneliti yang berhasil mensimulasikan sirkuit Sycamore 53-qubit milik Google menggunakan lebih dari 1.400 GPU dan teknik algoritma revolusioner.
Tim peneliti ini mencapai tonggak penting dengan mensimulasikan sirkuit kuantum Sycamore 53-qubit, 20-layer milik Google. Pencapaian ini diwujudkan menggunakan 1.432 GPU NVIDIA A100 dan algoritma paralel yang sangat dioptimalkan, membuka peluang baru untuk mensimulasikan sistem kuantum pada perangkat keras klasik.
Inovasi dalam Algoritma Tensor Network
Inti dari pencapaian ini adalah teknik kontraksi tensor network yang canggih, yang secara efisien memperkirakan probabilitas output dari sirkuit kuantum. Untuk membuat simulasi ini memungkinkan, para peneliti menggunakan strategi slicing untuk memecah tensor network penuh menjadi bagian-bagian yang lebih kecil dan lebih mudah dikelola.

Hal ini secara signifikan mengurangi kebutuhan memori sambil mempertahankan efisiensi komputasi sehingga memungkinkan simulasi sirkuit kuantum besar dengan sumber daya yang relatif moderat.
Tim ini juga menggunakan metode "top-k" sampling, yang memilih bitstring dengan probabilitas tertinggi dari output simulasi. Dengan berfokus hanya pada hasil probabilitas tinggi ini, mereka meningkatkan linear cross-entropy benchmark (XEB), ukuran kunci tentang seberapa dekat simulasi cocok dengan perilaku kuantum yang diharapkan.

Hal ini tidak hanya meningkatkan akurasi simulasi tetapi juga mengurangi beban komputasi, membuat proses lebih cepat dan lebih skalabel.
Validasi dengan Sirkuit Lebih Kecil
Untuk memvalidasi algoritma mereka, para peneliti melakukan eksperimen numerik dengan sirkuit acak skala lebih kecil, termasuk sirkuit gerbang 30-qubit, 14-layer. Hasilnya menunjukkan keselarasan yang sangat baik dengan nilai XEB yang diprediksi secara teoritis untuk berbagai ukuran sub-jaringan kontraksi tensor.
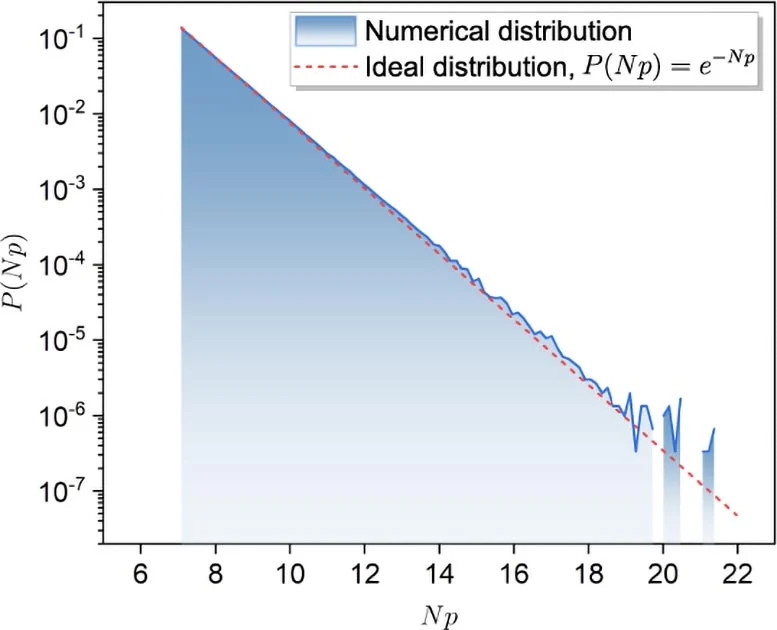
Peningkatan metode top-k terhadap nilai XEB selaras erat dengan prediksi teoritis, menegaskan keakuratan dan efisiensi algoritma.
Mengoptimalkan Kinerja Kontraksi Tensor
Studi ini juga menyoroti strategi untuk mengoptimalkan kebutuhan sumber daya kontraksi tensor. Dengan menyempurnakan urutan indeks tensor dan meminimalkan komunikasi antar-GPU, tim mencapai peningkatan signifikan dalam efisiensi komputasi.
Strategi ini juga menunjukkan, berdasarkan perkiraan kompleksitas, bahwa peningkatan kapasitas memori seperti 80GB, 640GB, dan 5120GB, dapat secara signifikan mengurangi kompleksitas waktu komputasi. Penggunaan konfigurasi memori 8×80 GB per node komputasi memungkinkan komputasi kinerja tinggi.
Masa Depan Simulasi Kuantum
Terobosan ini tidak hanya menetapkan tolok ukur baru untuk simulasi klasik komputer kuantum multi-qubit tetapi juga memperkenalkan alat dan metodologi inovatif untuk penelitian komputasi kuantum masa depan.
Dengan terus menyempurnakan algoritma dan mengoptimalkan sumber daya komputasi, para peneliti mengantisipasi kemajuan substansial dalam mensimulasikan sirkuit kuantum yang lebih besar dengan lebih banyak qubit. Karya ini mewakili kemajuan signifikan dalam komputasi kuantum, menawarkan wawasan berharga untuk pengembangan teknologi kuantum yang berkelanjutan.














